- Build Everything
- Posts
- Everything You Need To Know About Designing A Rate Limiter - Part 1
Everything You Need To Know About Designing A Rate Limiter - Part 1
Master your next system design interview by learning how to design a high-performance, scalable rate limiter.
Ben Osborn
February 15, 2025
What are we building?
Rate limiting is a really simple concept: you have some services that you want to limit the number of traffic to in some way, i.e. if you are getting too many requests, it is better to drop some of them than have your entire application go down. Maybe this is to protect your service from malicious requests, or maybe to protect resources such as in the case where you consume some third-party API, or even to prevent the abuse of your service which degrades it for others.
In practice, your rate limiter will receive the request, figure out if too many requests have already been made, and if they have been, drop the request.

Today, we’re going to think about how you can implement a rate limiter at an enormous scale (think millions of concurrent requests), and eventually produce a design capable of doing so, whilst considering the different possibilities.
How should this work?
To begin, we have some big questions we should ask that will be fundamental to our design, which we must tackle before we start architecting. By answering these questions, we will eventually reach an optimal solution for our design.
What should we rate limit on?
Where should our rate limiter sit?
How should we do the rate-limiting?
How can we scale this up to ensure high availability and performance?
For functional requirements, we simply want to take a request based on some parameters and determine whether that request should be allowed.
For non-functional requirements, the system should be:
Highly-available and fault-tolerant.
Performant and does not add significant latency to the system.
Able to scale out to handle concurrent requests from millions of users.
Enforce rate limiting measurements consistently (i.e. if we only allow 5 requests per minute, the user should not be able to make 6 requests in a minute).
What should we rate limit on?
It’s easy for us to say “Let's limit the number of requests”, but conceptually, we need to attach this limit to some piece of data. What we choose will affect the scalability of our design. Let’s consider a few different approaches we could use to do so:
Service rate limiting.
User ID rate limiting.
IP address rate limiting.
Service rate limiting
For this, we allocate a flat amount of requests to a particular service, and every request contributes to this quota.
For example, let's say I have service A and give it a quota of 1000 requests per minute. I then have 2 users, user 1 and user 2. They each make 500 requests each successfully within a minute. Any additional requests they make during that minute will be dropped.
Whilst this is a simple approach, there are some big problems:
Unfair resource allocation: what if user 1 is greedy and consumes 999 requests, leaving only 1 request for user 2?
Bottleneck: keeping our rate limiter at a service granularity, makes it very difficult to eventually shard our rate limiter, which might make it difficult to scale our service later on.
User ID rate limiting
With this approach, we instead use the user ID as a rate-limiting key. This is fairly practical, as we most likely have the user ID sent through to every service as part of the request if the user is authenticated. It is also fair, as we allocate each user a certain number of requests in some time range, which does not affect other users’ limits. Additionally, our user ID is fairly fine-grained and can be easily sharded across multiple servers, helping us to eventually scale.
However, let's consider the situation where the user is not authenticated - how can we get the user ID if we do not know who the user is? Also, what happens if the user keeps making new accounts? You can probably solve this one in practice by fixing your signup process, but it's worthwhile thinking about.
IP address rate limiting
Another approach is to rate-limit based on the user's source IP address. Unlike user ID, you should always have this (except for some malicious cases where this request should probably be dropped anyway). This has similar benefits to the user ID approach, however, there are some things we need to consider:
What happens if multiple users use the same IP address and we rate limit, i.e. university wifi or VPN?
What is stopping the user from spoofing their source IP address?
NOTE: Your rate limiter will likely sit behind a load balancer, so if you use the direct source address you will get the IP address of the load balancer, which would not be good! To fix this, you can use the X-Forwarded-For header provided by most layer 7 load balancers. Layer 4 load balancers can also support this functionality using proxy mode.
A practical approach
In practice, our rate limiter will only need to rate limit on some kind of key - so we can use multiple things to rate limit on. If we have the user ID, we can use the user ID as our key, but if we don’t we can fall back to using the IP address. This serves as a happy medium.
In addition, we will also likely rate limit based on the actions the user is performing. For example, maybe we allow 100 read requests, but only 10 write requests per second. Breaking down the type of action will further reduce our rate limit granularity, which will eventually make it easier for our system to scale.
Also, maybe there is some better piece of data for your system that you can rate limit on? Systems design is about being creative, so get thinking!
Where should our rate limiter sit?
There are a couple of spots where you can put your rate limiter into practice, each having its own set of tradeoffs.
Client side.
On the service itself.
Middleware layer.
Client-side
This is the easiest approach, as the clients throttle their requests and keep track of them themselves. With this, we don’t even need a rate-limiting system, the client just needs to keep track of the number of requests they have made in memory, and then if a certain number of requests has been made during a given period, don’t send any more requests.
Imagine we have a React frontend application. We can have this rate-limiting function applied to each of our API calls as a wrapper like the following:
function rateLimit(apiCall: () => Promise<void> | null) {
// Update global rate limit count
// If rate limit has been reached, return error
// Else, execute the request and return the result
}
The benefit of this is that it is simple. We don’t need to worry about user IDs or rate-limiting keys, failures of distributed systems, concurrency, locking, or availability. In addition, if the user has made too many requests, we don’t even send the request to the server, which reduces our network bandwidth and the load on our gateway layer (i.e. an API gateway or a load balancer).
This is particularly useful as a form of defensive program. Many front-end API calls in modern single-page applications charge on a per-request basis (think Firebase). Many developers have been subject to unexpected 70k monthly bills where a frontend bug has made too many requests. This helps mitigate this, and will at least buy you some time.
Whilst this solution will work for the majority of users who are doing the right thing, it does not prevent malicious users from disabling this rate limiter by modifying the code, or even bypassing it and calling your API directly.
However, because of its simplicity and the benefits it provides, I think it should not be overlooked and can be used in conjunction with some approaches that we will discuss now.
Service-side
I am calling this service-side because I mean we can implement the rate limiter logic on each service directly. The diagram below should clear this up.

We see in this setup, each service is responsible for rate limiting itself. The user sends a request to the load balancer, the load balancer forwards it to the service, and then the service decides whether or should process or drop the request.
With this approach, we have the benefit that each service can independently manage its rate-limiting logic. However, this isn’t a huge benefit in itself, as in practice you probably don’t need the logic to differ.
There are a few ways we can implement this. One approach would be to have a dedicated rate-limiting SDK that handles all of this logic. However, with this approach, you still need to manage dependencies and things such as ACLs if you use an external service (such as Redis) to manage your storage for your rate limiter (if you go down that route), so it is not a perfect abstraction.
Using an SDK introduces its own set of issues, such as maintaining and upgrading versions between microservices. i.e. if you want to upgrade your rate limiting logic, you need all services to upgrade their rate limiting logic, and how this upgrade will affect the existing implementation (i.e. if you have some in-memory data structures in Redis and you change formats). Also, it is still up to the developer to introduce the rate-limiting themselves into their code - you can bring a horse to water, but you can’t force the horse to drink it.
But who says we need to use a distributed data store like Redis, maybe in some cases to reduce latency and complexity, if we don’t care too much about consistency of our rate limiter i.e. if we throttle or allow slightly more or fewer requests than specified, and we just need it for burst control, we could just keep the rate limiting information in memory of each service using some form of LRU cache. We could then set the max allowed requests for each node in that service cluster to add up to the total allowed requests across all our services. In practice, this might be difficult, as to start we are now consuming more of the machine's memory resources just for rate-limiting. In addition, introducing an eviction policy helps fix the size of the memory, but now we might allow too many requests from users. Also in practice, if our gateway that calls the service uses some kind of consistent hashing, the load of the user's requests might not be equally balanced across all nodes in the service cluster, resulting in them hitting a much smaller rate limit than the expected overall cluster rate limit. Furthermore, since we keep all data in memory, every time a pod restarts in our cluster (which happens more in practice than you’d think), the user's rate limits are reset.
Maybe a more favorable approach, if your company is using Kubernetes, is to use a sidecar pattern, where you have a dedicated rate limiter container that proxies all traffic to your application container within a pod. With this approach, you can force all applications to use rate limiting at the infra level and can configure the rate limiting configuration within the sidecar itself (which you control through Kubernetes for the entire organization). If you need to upgrade the rate limiter, you can force all applications to upgrade by editing the configuration without needing to modify and redeploy the code. You can also abstract the concept of rate limiting entirely away from the developer - they can just write the code and you deploy it by injecting it into all pods.
Some key issues that come from this approach are that the request still hits the service and consumes precious computing resources. Whilst the time to process dropped requests should be significantly less than allowed requests, it still consumes resources. In the case your service gets DOS’d, it will be able to withstand more traffic, but it will still impact the performance of allowed requests. This is because whatever approach you take, your rate limiter is sharing the same underlying resources as your application.
Middleware (gateway level)
With this approach, we move all rate-limiting logic to the gateway, being an intermediary service called directly by the client which calls our other service. This might be a load balancer or an API gateway. The gateway will get the request, check if the rate limit has been exceeded, and if it has returned a 429 status code along with the next retry time to the client where they can retry, otherwise, it will send the request downstream to the service.
The major benefit here is that the service is protected from requests that would be dropped. You might say, well regardless of where I put the rate limiter on the server side, who cares if it brings down my API gateway/load balancer or the service itself, if one of them goes down my application can’t work anyway! In some trivial applications, you might be right. However, in practice, microservice architectures are a spaghetti mess. If your gateway service goes down, it prevents new requests from entering the system. However, if one of your core services goes down, other services might rely on it, which may lead to high message queue lag or cascading failures if your services make synchronous calls. I.e. with this rate limiter we are designing, we want to limit new requests from entering our system, whilst protecting data that already exists within our system.

Other benefits mean that all of our rate limiting logic is centralized in a single place, and is entirely managed by the gateway which is entirely abstracted away from the rest of our services, no need to worry about Redis ACLs! It’s also quite simple, and many existing services such as AWS API Gateway provide this functionality for you.
Just to clarify how this works, here is a diagram:
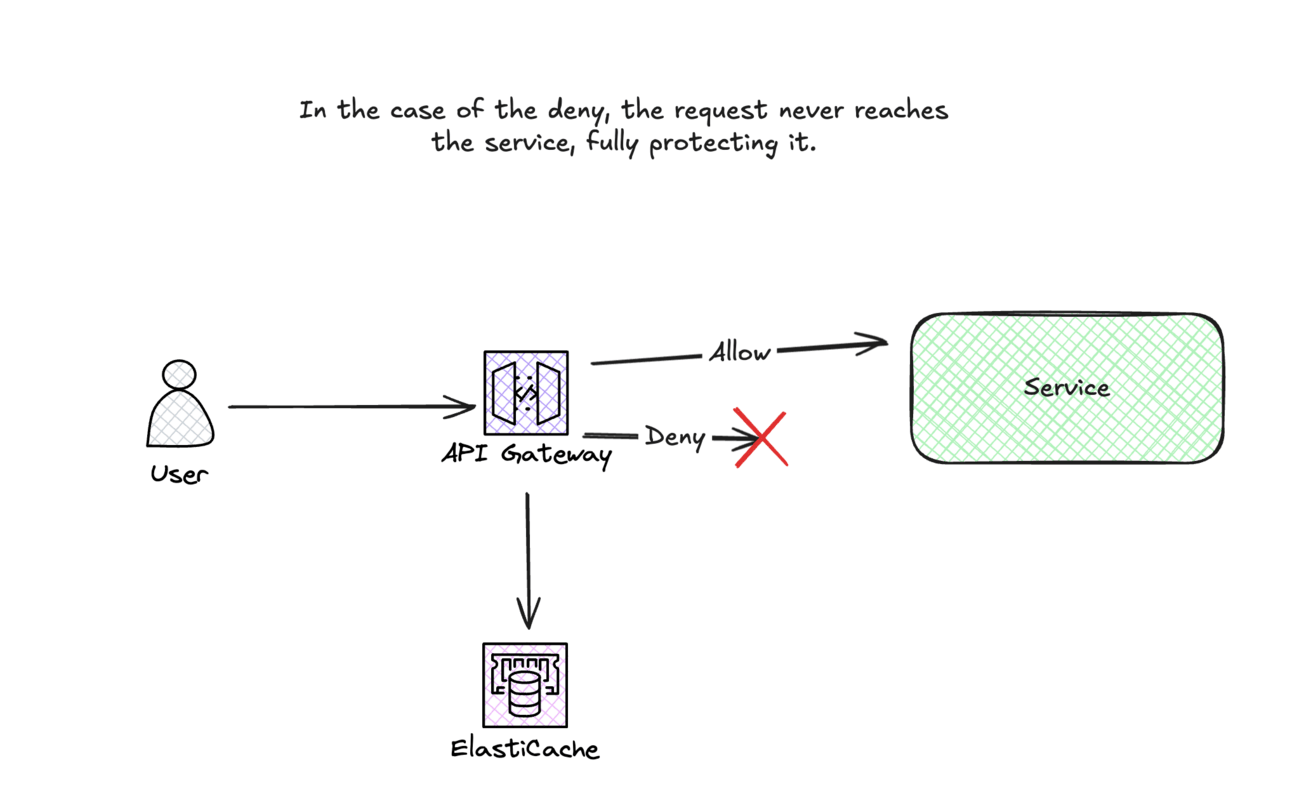
Alternatively, you could also move the rate-limiting logic outside of the API gateway into its service. However, it would potentially add more latency as we now need to go from API gateway → rate limiting service → Redis instead of API gateway → Redis. However, in situations where multiple services need to call the rate limiter individually, it might make more sense to do this and have the logic consolidated in a central location.
To follow up on a point mentioned in the service level rate limiter, it is worth noting that if we know how requests are distributed to our API gateway (i.e. all requests from the same user ID go to the same node in the API gateway) and we are mostly trying to prevent burst and don’t need an exact rate limit, we can potentially introduce some level of local caching using a write back approach, where we use an LRU policy to keep our rate limit information locally to avoid a network trip, then update the shared Redis when the rate limit key is evicted or periodically in the event of a service crash. This can help reduce latency, at the expense of data consistency of course. To improve the consistency, we can also use a consistent hashing approach to ensure the same rate limit key is sent to the same server. Depending on the volume and size of our keys, we might be able to fit them entirely into the memory of the API server, and as long as we are OK with some rate limit data loss in the case of a restart, we can eliminate the need for Redis.
Conclusion
Since this has already been a long read, we will break the design into multiple parts. In this section, we've introduced the problem, outlined the constraints we must work within, and discussed high-level architectural decisions, including where we will place our rate limiter and what we will rate limit.
In the next section, we will explore rate-limiting algorithms in detail and discuss how we can use them to design a rate limiter that meets our requirements.
Click here for part 2!