- Build Everything
- Posts
- How To Build A Discord Clone - Part 2
How To Build A Discord Clone - Part 2
Impress your next system design interviewer by learning how to build your very own, highly scalable Discord clone.
Ben Osborn
February 24, 2025
Continuing from last time
In part 1, we started designing our own Discord clone implementation, and addressed the following functional requirements:
Adding friends.
Sending DMs to friends.
In this section, we will tackle the following requirements:
Message persistence.
Client-side implementation.
Receiving messages after being offline.
Receiving notifications for messages.
Users have a history of all messages.
Currently when we send messages, only users who are currently online will receive the messages, and we have no way to persist messages. Discord allows us to log in to a new device and get our entire message history. Therefore, we need some way to persist messages. We also need some way to introduce idempotency into our system, and you will see that by introducing the history, this will become trivial.
To start, we need to introduce a database which will store our events. We need to first consider the read/write ratio before choosing a database. Instead of having to read our entire message history every time we load the conversation, in practice, we can store the chat history on our device (cache locally). This means our read-throughput will be quite low. However, we will need to write for every message, which leads to high write throughput. We do not need transaction support or strong consistency, as we will mostly just be inserting new messages. We still need high durability, but it does not matter if it takes a while for the message to be readable from the database, as we will receive the message in real-time anyway.
Since we need high write throughput, and we don’t care about transactions or consistency, the best choice here is Apache Cassandra backed by SSDs, which uses an LSM tree for super fast write ingestion and supports automatic sharding through the partition key, which will be useful for us. It also uses leaderless replication, allowing us to tune our consistency tolerance for higher write availability in the case a node in our cluster goes down. Our partition key can take the form user1:user2 in lexicographical order (to guarantee the same order i.e. when we create the ID the order will always be correct from the sorting), and our sort key can be the messageID from before. Because our message ID uses snowflake ID which has a prefix of a 32-bit timestamp, our messages will be sorted by creation time. Discord uses a variation of Cassandra written using C++ https://discord.com/blog/how-discord-stores-trillions-of-messages, so this is how we can know we are on the right path.
By using this setup, our key for a row consists of user1:user2 and messageID, and this means if we ingest a duplicate message, as long as it has the same message ID, it will have no effect, making our system idempotent. We can also add an insert condition so that we check if the message exists first, which might be useful for change data capture (depending on how our CDC mechanism works), so we don’t trigger another event from a duplicate insert.
To ensure our idempotency takes place and acts like a filter for new messages being sent, and to ensure we only send a message after we persist the message (which might otherwise lead to some weird problems), we can introduce change-data-capture onto our Cassandra table so that after a message has been persisted, it will enter a Kafka queue where it will be eventually sent out.
Finally, we have a new service for retrieving the persisted messages through a paginated API, where we can set which conversation we want to retrieve messages from, the page size (the maximum messages we can receive in a single request), and what page we are currently up to.
We will update our architecture to replace the routing service with a new messaging service, which takes care of routing but also persisting and retrieving messages.

One thing to know is using this CDC approach introduces some additional latency into our system for delivering messages. If latency is critical to us and we do not care if a message received by the user does not persist, we could perhaps forward the message at the same time we write to the database. Alternatively, we could have our code set up so that we only send the message after the write to Cassandra succeeds, but this will not guarantee that our message is delivered immediately. Because of another requirement for our system that we will introduce soon, I think the CDC approach will work best for now, and the extra latency should not be significant.
Storing data is a pain, and with our current approach, we need to store everything forever. It is company-dependent, but what would be ideal is to have a message retention period, where after this time the message is deleted or archived to some offline table which is cheaper, making it inaccessible to the user.
If we had very high write throughput, it is possible our database might become overwhelmed which would lead to high latency or timeouts when trying to send a message. To decouple our write ingestion from our write processing and message storage and forwarding, we could introduce a message queue such as Kafka where we first write the message, and then our messaging service could consume these events and process them at its own rate. However, this may introduce additional latency in our system. If our application is latency-sensitive, it might be better to just return the error to the user so they can retry. However, since our database is sharded on conversation ID, as long as we have sufficient shards, most conversations are unlikely to produce enough messages to overwhelm the shard. In the case where we have some malicious users flooding a conversation with requests, we can introduce a rate limiter with a rate-limiting key consisting of the conversation ID and the user ID.
Client-side implementation
Before we continue, let's outline how our current system will work from the client side. When the client opens up the chat, if it is the first time, they will fetch the first few pages of conversation history from the API we proposed earlier. When users receive new messages from the websocket, they will be added to our history.
All of these messages are stored on our device, and messages older than a certain time period will be cleared from the device to free up space, if we want to go back further in history we must use our pagination API. Our messages will be stored in sorted order using a sorted set implemented using a skip list. If we receive a duplicate message, we look it up in our list and ignore it if it already exists.
When users log in after being inactive, they receive all new messages
Most of us do not sit on our devices all day. However, when we log in to Discord, we receive a full list of all the messages we missed to keep us up-to-date. This is what we will be attempting to implement here.
But don’t we already have this in our current implementation? We can just query our message history API every time we log in until we see a message that we have already seen. But what happens if a message is never delivered to us when we are online i.e. the server crashes, or we shut down our device before it crashes? Now, we have gaps in our message history. One approach we could take is to assign a sequence number to our chat history, such that every time we send a message we increment the counter, similar to TCP.
For example, if we have our chat sequence and have sent 5 messages, the user can only ack the next message in the sequence they are up to. So if they receive messages 1, 2, 3, 5, we ack up to 3 and send that back to the server. The server now tries to resend 4 and 5, and now we ack 5, the server knows it has no more messages to send us.
However, the challenge with this approach is keeping track of this incremental ID. We already mentioned that we will use a snowflake ID for our message ID, which does not guarantee strict monotonicity (i.e. different worker ID at the same timestamp) and allows for gaps. We could instead keep track of a counter per user conversation which we will use to replace our message ID, but now we need to keep track of this counter. Also, if we use this counter, we cannot guarantee idempotency, as the server has to generate the counter for us to maintain consistency (which requires locking, acts as a bottleneck, and introduces its own set of problems…). To guarantee idempotency, we must generate the idempotency key at the source.
Another approach we could take is to explicitly keep track of all messages that have not been acknowledged for each client ID of both the sending and recipient user, and then continue to send them through until they have been acknowledged. We can repeatedly send these messages over to the user through the keep-alive mechanism, acting like polling, which is OK as this is a simple data reconciliation job and does not require real-time. However, with this approach, we need to use some additional space on the server side to keep track of what messages the clients have not seen. However, upon acknowledgment, we can delete these messages from the table.
But what happens if the user goes inactive forever? Do we just maintain this data indefinitely? The answer is no, but how can we achieve this? To start, we say that periodically, the user must re-fetch their latest messages using our pagination API. When they refetch, they will have a complete history of all messages, so we do not need to maintain the latest messages anymore, and therefore we can set a time to live on our inbox messages as the time taken for this period to occur, as we guarantee that the user will either receive the message from the inbox or refetch it themselves.
So how will this work? We need to maintain an additional Cassandra table for our user ID and client ID pairs. We can use a combination of the client ID and conversation ID client1:user1:user2 as the partition key, and the message ID messageid as the sort key. We can reuse our existing Kafka topic that uses CDC off the main table to publish messages in a consistent way, making sure to add the TTL of our refresh period as discussed earlier.

Users get notifications for all new messages
In this case, when we are not online, we want to receive new notifications about it. This may differ depending on our device, such as push notifications on mobile, and desktop notifications. For this change, we will consider allowing a user to change their notification settings is out of scope, and we will assume we can send notifications to all users for all messages if we want. Most notification providers (i.e. app push notifications) allow you to disable the notifications at the app level anyway, so we at least have device-level permission granularity out of the box.
In short, building a notifications service is very complex. If we want to do some optimization, it might require a separate system design in itself. Because of this, for now, we will keep it very simple, but look out for another system design from me soon.
To keep it simple, we will have a separate service that listens to our Kafka new messages topic and sends the notification. Because we might have different application types that might have different processing logic, in some cases it might make sense to have a separate service for each notification type which has its own special logic. However, to keep it simple, we will have one service that maintains its own database, where the primary key will consist of the user ID and the client ID (partition key = user ID, sort key = client ID), representing the device that we need to send notifications to.
The service will have an endpoint to add API information. When the user logs into the client for the first time, the device will ask for permissions, and if the user allows it, we will get back this unique data required for sending information to the device. From here, we will invoke this endpoint which will receive the device type (a simple enum we can define for all the devices we support in our system), as well as the identifier data for sending the notifications.
The service will work as follows using the following pseudocode:
type Message struct {
FromUserID int64
ToUserID int64
Message string
MessageID int64
}
type Client struct {
UserID int64
ClientID int64
DeviceType DeviceType
DeviceInfo interface{}
}
func SendNotifications(message *Message) {
userID := message.UserID
// Get all of the devices for which we are allowed to send notifications
var clients []*Client = db.getClientsByUserID(userID)
// Send each device to its own handler for the message
for _, client := range clients {
switch client.DeviceType {
case DeviceType_iOS:
IOSHandle(client, message)
}
}
}
func IOSHandle(client *Client, message *Message) {
iosDeviceInfo := message.DeviceInfo.(*IOSDeviceInfo)
// Call the IOS push API
SendNotification(iosDeviceInfo, message.Message)
}
Here is the updated architecture:
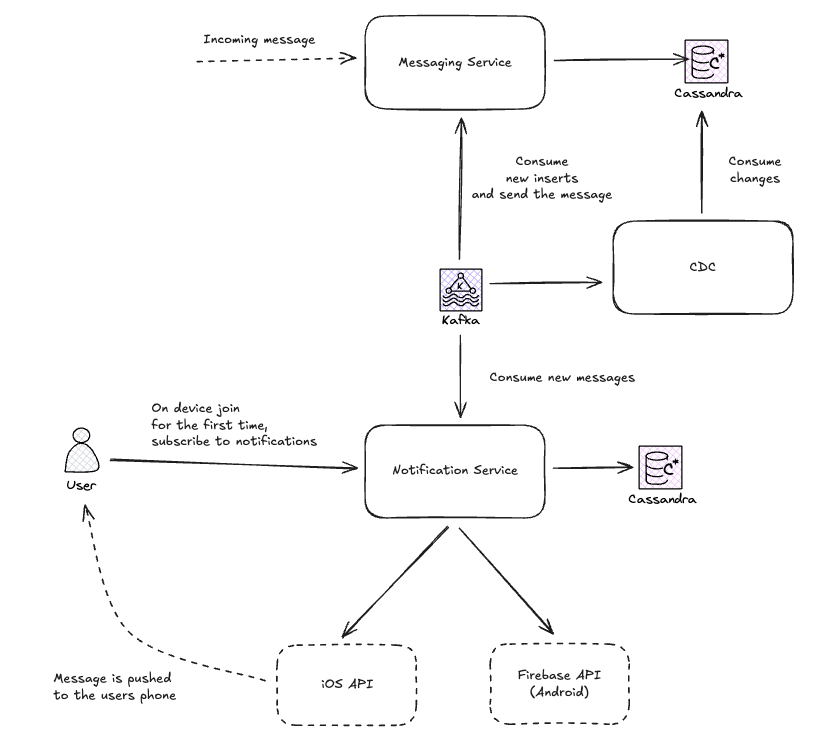
While this approach works and satisfies our requirements, it is crude and has a few major flaws. To start, what about idempotency? In general, we require idempotency from end-to-end, so whilst we support an idempotency key from our unique message ID, we cannot guarantee that our downstream APIs will support this for us. If the downstream does not support idempotency, maybe we can do some optimization to reduce duplicate calls by keeping track of what messages we have already sent to the downstream and preventing repeated calls. However, this is not a perfect solution and still has edge cases. But does it matter that much if rarely we send a notification to the user twice?
The main issue here, apart from the lack of granular control the user has over which messages they receive (which is out of scope for this design), is the frequency at which we send messages. First, we might overwhelm the user if they are part of a big server, which is likely to cause them to block us and not use our app again. It would be better if we could do some rate limiting on our behalf and be smarter about what messages we send. For example, in an ideal system, for the first few messages we might send them directly to the user, and then if we continue to send messages while they are offline, we aggregate them and introduce some frequency control and instead say “5 new messages”, and then when the user comes online we clear this and start again. This is why I think it makes more sense to introduce this as part of a separate system design.
Keep reading
Thanks for reading part 2! If you’re from the future, part 3 should already be available, where we will complete our design by implementing the following features:
Sending attachments.
Presence indicators (i.e. active, away, offline).
Messaging with servers/rooms.
Again, thank you so much for reading I greatly appreciate it! It would also mean a lot to me if you could share this with anyone interested in system design or preparing for an upcoming interview, and I would be eternally grateful!
Click here for part 3!